JavaScriptの文字列を反転する10の方法とそのパフォーマンス
はじめに
JavaScriptで文字列を反転する10の方法を(無理矢理?)思いついたので、ちょっと簡単に紹介したい。また、それぞれについて、各ブラウザでパフォーマンスを測定してみたので、その結果も合わせて載せる。
文字列のStringオブジェクトには、部分切り出し(substring, slice)や置換(replace)、連結(concat)など豊富な機能があるのに、反転(reverse)機能はない。Arrayのreverseはあるのに、Stringのreverseがないのはどうしてなのだろうか。
各ブラウザとそのバージョンは以下の通り:
| Chrome | Firefox | Opera | Safari | IE |
|---|---|---|---|---|
| 13.0.782.112 m | 6.0 | 11.50 | 5.1(7534.50) | 8.0.7600.16335 |
rev01: C言語的発想
空の配列を作って、そこに元の文字列の後ろから1文字つづ入れていって、最後に文字列として連結する。日本語文字などが混在していても、もちろん問題ない。
function rev01(s) { var rv = []; for (var i = 0, n = s.length; i < n; i++) { rv[i] = s[n - i - 1]; } return rv.join(""); }
結果は以下のグラフ。横軸は文字列の長さ、縦軸は100回繰り返したときに要する時間(ミリ秒)。以降のグラフも同様。

IEは他のブラウザと比べて断トツに遅すぎて、同じスケールのグラフでははみ出してしまう。
rev02: JavaScript初心者的発想
rev01とほとんど同じだけれど、配列を作らないで、文字列のまま+オペレータを使って連結していく。
function rev02(s) { var rv = ""; for (var i = 0, n = s.length; i < n; i++) { rv = rv + s[n - i - 1]; } return rv; }
+=オペレータを使うと多少効率がよくなるだろうか。
function rev02b(s) { var rv = ""; for (var i = 0, n = s.length; i < n; i++) { rv += s[n - i - 1]; } return rv; }

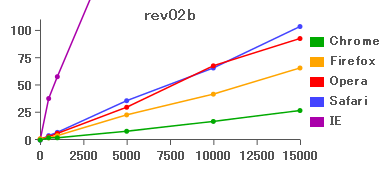
両者に殆んど違いはないが、Firefoxは += を使った方が若干速くなったようだ。
+オペレータによる文字列の連結はナイーブな実装の場合、文字列をその時点でコピーするので、非常に遅いという印象があるが、その辺りは工夫がされているようだ。実際rev01より高速になっている。しかし、これには理由があるので、別の機会に触れておきたい。
rev03: JavaScript中級者的発想
一文字づつ配列にばらして、その配列を反転して、文字列として結合。あたりまえだけど、split, reverse, joinなどの関数の存在を知らないと作れない。
function rev03(s) { return s.split("").reverse().join(""); }
恐らく、これが最も短いコードでの実装だと思う。パフォーマンスも実用的。

rev04: 天邪鬼的発想
文字列を文字コードの配列に変換して、それを反転したものから文字列を生成する。
ちょっと遠回りな方法なので、普通こんなコードは書かないと思う。
function rev04(s) { return String.fromCharCode.apply(null, Array.prototype.map.call(s, function (x) { return x.charCodeAt(0); }).reverse()); }
IEはmap関数が組込みでは実装されていないようなので比較から外した(IEがないのは以下も同様)。

rev05: 文字列は文字の配列だ的発想
やっていることはrev01と同じ。それにしても、forEachという名前はバランスが悪い。eachだけでよいのにと思う。
function rev05(s) { var rv = []; Array.prototype.forEach.call(s, function (x) { rv.unshift(x); }); return "".concat.apply("", rv); }
unshift()関数は配列の先頭に要素を挿入するので、インデックスの書き換えが全体に渡って行われるため、効率が悪いことが予想される。
そこで、push()で配列の最後に要素を挿入して、全部push()した後にreverse()する方が効率がよい。
function rev05b(s) { var rv = []; Array.prototype.forEach.call(s, function (x) { rv.push(x); }); return "".concat.apply("", rv.reverse()); }
結果を見て分かるとおり、両者は桁違いにパフォーマンスが違う。


ちょっとここで、Array.prototypeのプロパティで定義されている関数群について補足しておこう。Arrayの関数のほとんどはArrayオブジェクト以外にも適用できるジェネリックな関数である。つまり、Arrayのようにゼロ以上の整数値(の文字列)をプロパティ名として各要素をアクセスできて、かつ、要素数を意味するlengthプロパティがあるようなオブジェクトであればArrayオブジェクトでなくてもArrayの関数は適用できる。文字列も整数値で要素がアクセスできてlengthプロパティを持つのでArrayのforEach関数は適用できる。
Arrayの関数が文字列に対して適用できるなら、Arrayのreverseも文字列に対して実行できるのではいか、と思いたくなるがそれはできない。Arrayのreverseは破壊的reverseなのである。Rubyで言えばreverse!、Lispで言えばnreverseである。JavaScriptの文字列はimmutable(要素を変更することができない)なので破壊することはできない。
rev06: Lispプログラマ的発想
Lispの教科書で最初に登場する再帰関数が恐らくappendとreverse。そのreverse的に書いたのが以下。処理系によっては文字列の長さが長いと簡単にスタックオーバーフローしてしまう。
function rev06(s) { return s.length <= 1 ? s : rev06(s.substring(1)) + s[0]; }
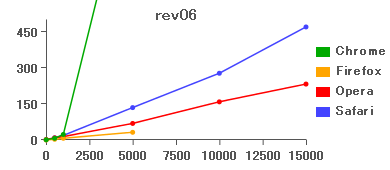
Lispでもこれに相当するものはスローリバースと呼ばれているくらいだから、本当に遅い。Firefoxの線が途中しかないのは、スタックオーバフローが発生しているため(以降のグラフも同様)。IEは計測不能なくらい遅い。それにしても、Chromeが遅すぎるのはどうしたことか。
rev07: シェーカーソート的発想
rev06と似ているけれど、先頭と最後の文字を交換して、その間に挟まれた部分文字列を再帰的に反転して三者を結合する。シェーカーソートとは全然関係ないこれど、双方向から狭めていくイメージが似ているため、その名前を使った。
function rev07(s) { return (s.length < 2) ? s : s[s.length - 1] + rev07(s.substring(1, s.length - 1)) + s[0]; }
rev06とちょっと違うだけなのに、Operaが極端に遅くなっている。

rev08: 分割統治法的発想
「文字列を左右半分に分けて左右を交換して結合する」を左右それぞれについて再帰的に行う。
function rev08(s) { var m = s.length >> 1; if (m == 0) { return s; } else { return rev08(s.substring(m)) + rev08(s.substring(0, m)); } }
プログラミングを覚えたての頃は、このような再帰的なコードを見ると、どうしてこのような宣言的な記述で結果が得られるのか不思議な思いがした。
ちなみに、s.lengthの半分を得るのにシフト演算子を使っているのは、結果が整数値になるようにするため。

rev09: 正規表現使いの偏屈的発想
発想はrev06と同じだけれど、正規表現を使って先頭文字と残りを切り出している。replaceの第2引数の関数の中で再帰している。つまり、照合した文字列(この場合文字列全体)を反転した文字で置き換えている。こんな無駄なことは誰もしないと思うが。
function rev09(s) { return s.replace(/^(.)(.*)$/, function (s, s1, s2) { return rev09(s2) + s1; }); }
最後の1文字を取り出す方式にすると以下のようになる。
function rev09b(s) { return s.replace(/^(.*)(.)$/, function (s, s1, s2) { return s2 + rev09b(s1); }); }
これもすぐにスタックオーバーフローしてしまう。両者にパフォーマンスの大きな違いはないようだ。
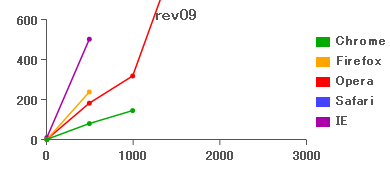

rev10: 関数型言語使い的発想
関数型言語ではmapとreduceが基本的な高階関数として登場するが、そのreduce関数と似たような動作をするArrayのreduce関数を使うと以下のように簡単に書ける。Arrayのreduceはジェネリックであるので文字列にも適用できる。reduceの第2引数の関数は引数を4個とるが、ここでは必要ないので省略している。initialValueに空文字を明示的に指定しているのは、sが空文字のときを考慮したもの。
function rev10(s) { return Array.prototype.reduce.call(s, function (prev, curr) { return curr + prev; }, ""); }
また、リストの右から順に適用していくreduceRight()を使うと、文字列反転は以下のようになる。
function rev10b(s) { return Array.prototype.reduceRight.call(s, function (prev, curr) { return prev + curr; }, ""); }
文字列反転の様子をトレースすると、こんな感じ。
rev10("abcde") => "a" + "" => "b" + "a" => "c" + "ba" => "d" + "cba" => "e" + "dcba" => "edcba" rev10b("abcde") => "" + "d" => "e" + "d" => "ed" + "c" => "edc" + "b" => "edcb" + "a" => "edcba"
両者でパフォーマンス上の大きな違いはないように思えるが、Operaでは大きな違いが発生した。
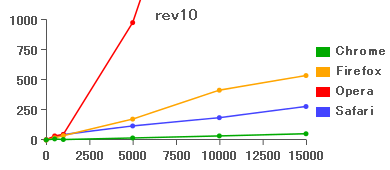

おわりに
結局のところ、「rev02: JavaScript初心者的発想」のものがブラウザ間の差異も考慮すると、一番高速であるようだ。ただし、そこでは文字列の連結が主要な部分を占めているが、処理系の実装によっては文字列の連結は実際にはその時点では連結しないで、リストのようにチャンクとして繋げているというものがある。そのため、文字列の反転自体は高速に見えても、その後、要素をアクセスしたときに実際の連結が発生して、それが遅いという可能性も考えられる。しかし、ここでパフォーマンス評価したような数千文字を超えるような文字列を扱うケースは稀であり、それが問題になることは実用上ほとんどないと思われるが、これについては別の機会で紹介したい(rev06でChromeが遅い理由がそこにあるのではないかと想像している)。
僕はプログラミングを覚えたての時の初歩的なアルゴリズムのテクニックの多くはLispから学んだ。リストの反転や並び替えなどの簡単なコードを書いているだけでも楽しかった。そういう素朴な楽しさというのは、今でも持ち続けているし、これからもずっと変わらないんだろうと思う。