皆既月食
遅ればせながら先日の皆既月食の写真をアップ。
普段の日だったら仕事中か帰宅電車の中なのであまり見られなかっただろうが、今回は土曜日なので十分に楽しめた。

Nikon D7000, Tamron18-270mm, F6.3, 1.0sec, iso640
ついでに木星を撮ったらどうなるだろうかとやってみた。とても見られたものじゃないけど、ガリレオ衛星もなんとか写っている。GIMPで画像処理。

さらに、レンズ性能が気になったので、シリウスを撮ってみた。中央付近の映像で、まぁ、こんなものか、という程度。ピクセル等倍を8倍に拡大。(270mm, F6.3, 1/100sec, iso800)

ところが、左上隅で撮ったのが下のもの。それぞれの隅で放射状になっているので、コマ収差なんだろうと思う。

ところで、iPhoneアプリのSkySafari3が凄すぎる。星は13等星まで表示できるし、星雲・星団はもちろんのこと、拡大すればその写真になり、木星や火星の衛星、土星の輪までシミュレートしている。今回の月食の様子もわかる。来年の5月21日は金環食が見られるが、07:34amに時刻を合わせると太陽と月がピッタリ重なるのも確認できる。これで無料だ。まさに神アプリ!
「MPEG-DASHとは何か?」のまとめ
MPEG-DASHについて勉強する機会があったので、今更ながら簡単にまとめてみた。
はじめに
- MPEG-DASH、その業界ではDASHと言えば通じる。
- DASHはDynamic Adaptive Streaming over HTTPの略。
- Adaptive Streaming ... なんかカッコイイ響き。
- ISO/IEC 23001-6 で規格化されている。
DASHの目的
- HTTPを使ってビデオのストリーミングを行う技術。
- ネットワークの帯域やビデオのビットレートや端末の性能などの問題を吸収。
- 再生が途切れない(再生中にバッファリング状態にならない)ように動的にコンテンツ(ビットレートなど)を切り替える。
- 環境に応じた最適な高品質のビデオストリームを提供できる。
- SkypeやNetflix、Huluなどでも似たような技術を使っている。
- DASHは普通のHTTPサーバで実現できるのが利点。
- AkamaiなどのCDNがそのまま利用できる。
- 従来の放送で利用されているストリームでは、複数のオーディオ/ビデオや字幕などを一本にmuxして端末(プレイヤー)側で必要なESを取り出すが、DASHはそれがサーバとクライアントに分散されたイメージ。
- 再生中にビデオのビットレートや解像度などを切り替えできるように、サーバには複数のビデオが予め用意されている。動的にエンコードしてもよいが。
- どのようなビットレートや解像度のビデオが提供されるかのメタ情報が定義される。
- このメタ情報をMPD(Media Presentation Description)と呼ぶ。
MPD - Media Presentation Description
- DASHは結局のところ、このMPDを規定する規格。
- MPDはXMLで記述される。
- MPDは1つのXMLツリーであるが、XLinkをベースにしたXMLなので部分木を必要に応じてダウンロードする。また、有効期限が定義されるので、MPD自身が動的に変わることもできる。
- MDPが動的に変わるのはVoDではなく、主にライブ(放送系)を意図している。
- MPDには抽象度の高いレベルから具体的なビデオのセグメントまで階層的に記述さる。
- MPDはざっくり言ってしまえば、MP4のmoov boxに相当するもの。
- MPDのトップレベルはPresentation。
- Presentationは完結した1本のビデオストリームを抽象化したもの。
- このPresentationレベルではタイトルや再生時間などは定義されるが、言語や解像度やビットレートなどは不定。とにかく一本のビデオというレベル。
- PresentationはPeriodの並びから構成される。
- Periodはビデオを時間でブツ切りに分割したもの。
- Periodにはstart時刻とduration時間が定義される。両者が計算できればどちらか一方でもよい。
- PeriodはGroupから構成され、GroupはRepresentationから構成される。
- RepresentationはSegmentから構成される。
- Segmentはメディアの最小単位。
- SegmentにはHTTP range GETで取得できるようにバイト位置や時刻情報などが記述されている。
- Segmentをつなぎ合わせられるようにIDRを考慮。
- 規格ではSegmentのガイドラインとしてFragmented MP4 (3GPPなど)とMPEG2-TSについて書かれている。
- 以上を図式化したもの。

結局何ができるようになるのか
ECMAScript Test262
ECMAScriptのテストケースが9/25付けで更新されていたので、各ブラウザについて実行させてみた。
- ECMAScript Test262
Test Suite Ver.: ES5 | Test Suite Date: 2011-09-25
ブラウザのバージョンは以下の通り:
| Chrome | Firefox | Opera | Safari | IE |
|---|---|---|---|---|
| 14.0.835.202 m | 7.0.1 | 11.51 | 5.1.1(7534.51.22) | 9.0.8112.16421 |
結果

| Browser | Pass | Fail | % |
|---|---|---|---|
| Firefox | 10829 | 187 | 98 |
| IE9 | 10693 | 323 | 97 |
| Chrome | 10589 | 427 | 96 |
| Safari | 10241 | 775 | 93 |
| Opera | 7264 | 3752 | 66 |
IE9が随分と健闘している。Operaはちょっと残念な結果。
まだテスト内容を確認していないが、恐らくFailしている大部分は重箱の隅系で実用上はそれほど問題ではないのだろうと思う(であれば良いのだが...)。
昭和記念公園のコスモス
ここのところ忙しくて休日もゆっくりできない日々が続いていたが、先週は実に久しぶりにカメラをもって出かけた。立川にある昭和記念公園。この公園には何度も来ているが、今回は2年ぶりくらい。

コスモスの丘とよばれる斜面一面にコスモス畑が広がっていた。

コスモスは宇宙や調和を意味するが、やはり、和名の秋桜がとても似合うと思う。

このようにふちがあるのは非常に少ない。横で写真を撮っていた年配のおじさんがピコティという品種だと教えてくれた。

これは白にピンクが滲んでいる。おそらく突然変異だとのこと。

これもピコティなのだと思うが、あかつき、という品種かもしれない。素人の僕には違いがよくわからない。

蜂も全身花粉だらけだ。

コスモスは弱々しそうな印象があるが、実は丈夫で逞しく雑草のように繁殖力に優れているそうだ。
品種については以下のページが役に立つ。
JavaScriptの文字列を反転する10の方法とそのパフォーマンス
はじめに
JavaScriptで文字列を反転する10の方法を(無理矢理?)思いついたので、ちょっと簡単に紹介したい。また、それぞれについて、各ブラウザでパフォーマンスを測定してみたので、その結果も合わせて載せる。
文字列のStringオブジェクトには、部分切り出し(substring, slice)や置換(replace)、連結(concat)など豊富な機能があるのに、反転(reverse)機能はない。Arrayのreverseはあるのに、Stringのreverseがないのはどうしてなのだろうか。
各ブラウザとそのバージョンは以下の通り:
| Chrome | Firefox | Opera | Safari | IE |
|---|---|---|---|---|
| 13.0.782.112 m | 6.0 | 11.50 | 5.1(7534.50) | 8.0.7600.16335 |
rev01: C言語的発想
空の配列を作って、そこに元の文字列の後ろから1文字つづ入れていって、最後に文字列として連結する。日本語文字などが混在していても、もちろん問題ない。
function rev01(s) { var rv = []; for (var i = 0, n = s.length; i < n; i++) { rv[i] = s[n - i - 1]; } return rv.join(""); }
結果は以下のグラフ。横軸は文字列の長さ、縦軸は100回繰り返したときに要する時間(ミリ秒)。以降のグラフも同様。

IEは他のブラウザと比べて断トツに遅すぎて、同じスケールのグラフでははみ出してしまう。
rev02: JavaScript初心者的発想
rev01とほとんど同じだけれど、配列を作らないで、文字列のまま+オペレータを使って連結していく。
function rev02(s) { var rv = ""; for (var i = 0, n = s.length; i < n; i++) { rv = rv + s[n - i - 1]; } return rv; }
+=オペレータを使うと多少効率がよくなるだろうか。
function rev02b(s) { var rv = ""; for (var i = 0, n = s.length; i < n; i++) { rv += s[n - i - 1]; } return rv; }

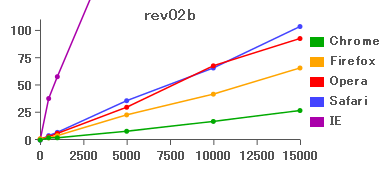
両者に殆んど違いはないが、Firefoxは += を使った方が若干速くなったようだ。
+オペレータによる文字列の連結はナイーブな実装の場合、文字列をその時点でコピーするので、非常に遅いという印象があるが、その辺りは工夫がされているようだ。実際rev01より高速になっている。しかし、これには理由があるので、別の機会に触れておきたい。
rev03: JavaScript中級者的発想
一文字づつ配列にばらして、その配列を反転して、文字列として結合。あたりまえだけど、split, reverse, joinなどの関数の存在を知らないと作れない。
function rev03(s) { return s.split("").reverse().join(""); }
恐らく、これが最も短いコードでの実装だと思う。パフォーマンスも実用的。

rev04: 天邪鬼的発想
文字列を文字コードの配列に変換して、それを反転したものから文字列を生成する。
ちょっと遠回りな方法なので、普通こんなコードは書かないと思う。
function rev04(s) { return String.fromCharCode.apply(null, Array.prototype.map.call(s, function (x) { return x.charCodeAt(0); }).reverse()); }
IEはmap関数が組込みでは実装されていないようなので比較から外した(IEがないのは以下も同様)。

rev05: 文字列は文字の配列だ的発想
やっていることはrev01と同じ。それにしても、forEachという名前はバランスが悪い。eachだけでよいのにと思う。
function rev05(s) { var rv = []; Array.prototype.forEach.call(s, function (x) { rv.unshift(x); }); return "".concat.apply("", rv); }
unshift()関数は配列の先頭に要素を挿入するので、インデックスの書き換えが全体に渡って行われるため、効率が悪いことが予想される。
そこで、push()で配列の最後に要素を挿入して、全部push()した後にreverse()する方が効率がよい。
function rev05b(s) { var rv = []; Array.prototype.forEach.call(s, function (x) { rv.push(x); }); return "".concat.apply("", rv.reverse()); }
結果を見て分かるとおり、両者は桁違いにパフォーマンスが違う。


ちょっとここで、Array.prototypeのプロパティで定義されている関数群について補足しておこう。Arrayの関数のほとんどはArrayオブジェクト以外にも適用できるジェネリックな関数である。つまり、Arrayのようにゼロ以上の整数値(の文字列)をプロパティ名として各要素をアクセスできて、かつ、要素数を意味するlengthプロパティがあるようなオブジェクトであればArrayオブジェクトでなくてもArrayの関数は適用できる。文字列も整数値で要素がアクセスできてlengthプロパティを持つのでArrayのforEach関数は適用できる。
Arrayの関数が文字列に対して適用できるなら、Arrayのreverseも文字列に対して実行できるのではいか、と思いたくなるがそれはできない。Arrayのreverseは破壊的reverseなのである。Rubyで言えばreverse!、Lispで言えばnreverseである。JavaScriptの文字列はimmutable(要素を変更することができない)なので破壊することはできない。
rev06: Lispプログラマ的発想
Lispの教科書で最初に登場する再帰関数が恐らくappendとreverse。そのreverse的に書いたのが以下。処理系によっては文字列の長さが長いと簡単にスタックオーバーフローしてしまう。
function rev06(s) { return s.length <= 1 ? s : rev06(s.substring(1)) + s[0]; }
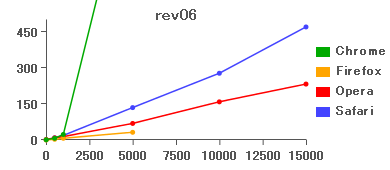
Lispでもこれに相当するものはスローリバースと呼ばれているくらいだから、本当に遅い。Firefoxの線が途中しかないのは、スタックオーバフローが発生しているため(以降のグラフも同様)。IEは計測不能なくらい遅い。それにしても、Chromeが遅すぎるのはどうしたことか。
rev07: シェーカーソート的発想
rev06と似ているけれど、先頭と最後の文字を交換して、その間に挟まれた部分文字列を再帰的に反転して三者を結合する。シェーカーソートとは全然関係ないこれど、双方向から狭めていくイメージが似ているため、その名前を使った。
function rev07(s) { return (s.length < 2) ? s : s[s.length - 1] + rev07(s.substring(1, s.length - 1)) + s[0]; }
rev06とちょっと違うだけなのに、Operaが極端に遅くなっている。

rev08: 分割統治法的発想
「文字列を左右半分に分けて左右を交換して結合する」を左右それぞれについて再帰的に行う。
function rev08(s) { var m = s.length >> 1; if (m == 0) { return s; } else { return rev08(s.substring(m)) + rev08(s.substring(0, m)); } }
プログラミングを覚えたての頃は、このような再帰的なコードを見ると、どうしてこのような宣言的な記述で結果が得られるのか不思議な思いがした。
ちなみに、s.lengthの半分を得るのにシフト演算子を使っているのは、結果が整数値になるようにするため。

rev09: 正規表現使いの偏屈的発想
発想はrev06と同じだけれど、正規表現を使って先頭文字と残りを切り出している。replaceの第2引数の関数の中で再帰している。つまり、照合した文字列(この場合文字列全体)を反転した文字で置き換えている。こんな無駄なことは誰もしないと思うが。
function rev09(s) { return s.replace(/^(.)(.*)$/, function (s, s1, s2) { return rev09(s2) + s1; }); }
最後の1文字を取り出す方式にすると以下のようになる。
function rev09b(s) { return s.replace(/^(.*)(.)$/, function (s, s1, s2) { return s2 + rev09b(s1); }); }
これもすぐにスタックオーバーフローしてしまう。両者にパフォーマンスの大きな違いはないようだ。
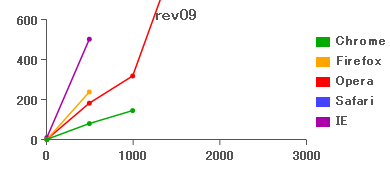

rev10: 関数型言語使い的発想
関数型言語ではmapとreduceが基本的な高階関数として登場するが、そのreduce関数と似たような動作をするArrayのreduce関数を使うと以下のように簡単に書ける。Arrayのreduceはジェネリックであるので文字列にも適用できる。reduceの第2引数の関数は引数を4個とるが、ここでは必要ないので省略している。initialValueに空文字を明示的に指定しているのは、sが空文字のときを考慮したもの。
function rev10(s) { return Array.prototype.reduce.call(s, function (prev, curr) { return curr + prev; }, ""); }
また、リストの右から順に適用していくreduceRight()を使うと、文字列反転は以下のようになる。
function rev10b(s) { return Array.prototype.reduceRight.call(s, function (prev, curr) { return prev + curr; }, ""); }
文字列反転の様子をトレースすると、こんな感じ。
rev10("abcde") => "a" + "" => "b" + "a" => "c" + "ba" => "d" + "cba" => "e" + "dcba" => "edcba" rev10b("abcde") => "" + "d" => "e" + "d" => "ed" + "c" => "edc" + "b" => "edcb" + "a" => "edcba"
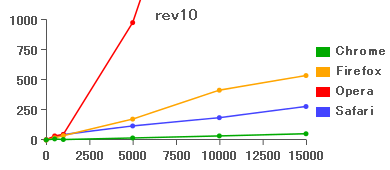
両者でパフォーマンス上の大きな違いはないように思えるが、Operaでは大きな違いが発生した。

おわりに
結局のところ、「rev02: JavaScript初心者的発想」のものがブラウザ間の差異も考慮すると、一番高速であるようだ。ただし、そこでは文字列の連結が主要な部分を占めているが、処理系の実装によっては文字列の連結は実際にはその時点では連結しないで、リストのようにチャンクとして繋げているというものがある。そのため、文字列の反転自体は高速に見えても、その後、要素をアクセスしたときに実際の連結が発生して、それが遅いという可能性も考えられる。しかし、ここでパフォーマンス評価したような数千文字を超えるような文字列を扱うケースは稀であり、それが問題になることは実用上ほとんどないと思われるが、これについては別の機会で紹介したい(rev06でChromeが遅い理由がそこにあるのではないかと想像している)。
僕はプログラミングを覚えたての時の初歩的なアルゴリズムのテクニックの多くはLispから学んだ。リストの反転や並び替えなどの簡単なコードを書いているだけでも楽しかった。そういう素朴な楽しさというのは、今でも持ち続けているし、これからもずっと変わらないんだろうと思う。
高いビルの上から物を落とすとどこに落ちるか?(あるいはプログラマとして心得るべきこと)
何の前触れもなく唐突に表題のような質問を周囲にすると、反応は概ね以下の4点に集約されるのではないか。
- えっ?どういうこと?(まっすぐ下に落ちると思うけど、何か引っ掛けかな?)
- 落ちる間に地面は東の方向に移動しているわけだから、真下よりちょっと西の方かなぁ?
- 地面は動いているけど、物も同じ方向に移動しているので、まっすぐ下に落ちるよ。
- 地球は自転しているから、高いところほど速く移動しているので、真下よりちょっと東の方じゃないの。
さて、正解がこの中にあるだろうか?多少の物理を理解している人であれば、4が正解であり、計算も正確にできると考えるだろう。2は何も知らない人の回答と思うかも知れない。
実はこの問題は、100%理科系少年だった僕が中学1年生のときの遠足の途中、歩きながら友達に出した問題である。近くにいた理科の先生がその話を聞いていたようで、問題を出したとき、ちょっと小馬鹿にしたように笑った。しかし、解答が4だということを説明したら、真顔になった。多分その理科の先生は3が答えだと思ったのであろう。そして友達は2と回答するのではと思ったのかも知れない。
しかし、4が本当に正解だったのだろうか?
先日、ふと、このことを思い出し、試しに会社で周囲の人達(ソフト開発者)に個別に同じ質問を投げてみた。さすがに2と答える人はいなかったが、大部分が3と答えた。
以下のような反応も期待したが、残念ながらこういった切り返しをしてくれる人はいなかった。
- 高いってどのくらい?宇宙(静止軌道上)まで届くような高さなら遠心力で落ちて来ないんじゃない?
- 空気の抵抗を考慮したらどこに落ちるかなんてわからないよ。
- 場所によって違うんじゃない?赤道上と北極や南極とでは違うよね。
- 月や太陽の影響や地球の公転を考慮したら計算は非常に複雑だよ。
- 物って何?「落とす」ということだから、重さのある固形物を想定しているのはわかるけど。ガス風船は落ちないよね。
- そんなことしちゃいけないよ。下の人に当たったらどうするの。
中学生だった当時はこのようなことは想定もしていなかったが、改めて考えると別の観点から問題が浮び上る。つまり、設問自体が曖昧で意味を持たなかったのでは?ということだ。質問した方もそれに気づかず、さらに、設問が曖昧であっても、質問を受けた方は暗黙の常識の範囲内で無意識に補ってしまい、意味のある設問に置き換えてしまう。そのこと自体を本人が知らない。
さらに、このクイズのような設問では、ヒントをもらう前にできるだけ自分で考えるということが暗黙の了解になっている。僕は決してクイズの積りで問題を出したわけではないのに、受けた側が勝手にそのように解釈してしまい、頭の中は疑問符でいっぱいなのに、あえて疑問を呑み込んでしまう。
ちょっとお遊びの積りで、10人程にこの設問を出していたが、途中でこれは単にこの話に限ったことではなく、ソフトウェア開発で僕らが日頃遭遇している問題に類似しているのではないかと思えてきた。
ソフトウェア開発で発生する問題の多くはコミュニケーション不足が原因である。コミュニケーション不足を引き起こす原因は、往々にしてその人の都合のよいように勝手に対象を解釈してしまい、確認すべき相手に確認しないことだ。「まさか、そんなことはないだろう」とか「当然、相手はそういう意図だろう」などの事実とは異なる思い込みをしてしまい、本人もそれに気づかないというパターンが多い。
そのような問題を回避するために、要所要所でface to faceのレビューが設けられるが、限られた時間で全てを網羅できるわけでもない。チームのメンバが声を出せば全員に届く範囲にいるような環境があれば理想的であるが、地理的に離れた複数の組織にまたがるような大人数のプロジェクトの場合にはそうはいかない。いわゆる「見える化」は困難であり、実行しようとすると極めて重いプロセスになってしまう。日頃の情報共有は、せいぜいメールやwebベースのプロジェクト管理ツールなど文章ベースで行われるくらいだ。
このような文章だけ(図や写真があっても同様だが)によるコミュニケーションでは、どうしても欠けるものがある。そもそも書かれている文章が舌足らずで意味がわからない、あるいは、多忙状態の中で自分も含め相手もちゃんと読んでくれない、といったことは日常茶飯事である。しかし、どういうわけか、どうとでもとれるような文章でもその真意を確認しないで、受けた方が勝手にいいように解釈してしまうケースが多い。後になって、そういう意味だったのか、と驚くこともある。冒頭で述べた設問の問題と同じなのである。
ある程度経験を積めば、潜在的な問題に対して、なんとなくおかしいといった感覚が発達するものである。それは文章や言葉の端々からくるものであり、相手が本当に意図していることと自分がその文章や言葉から理解した内容との間に微妙に生じたズレからくる心の隅に引っかかる微かな違和感である。
僕らは別々の人間である以上、どんなに文章や言葉で伝えても自分の頭の中にある真の内容を正確に相手に伝えることはできない。それは純粋に技術的な内容であっても、その人の持っている背景知識が異なれば、そのようなズレは容易に生じる。
疑うこと、あるいはちょっとした疑問からコミュニケーションが必要になる。コミュニケーションがなければ、もし潜在的問題があったとしてもそれを顕在化する機会が失われてしまう。しかし、相手の意図がはっきりしない場合に、それを正すような質問をしてもあまり有益でない。なにしろ、本人は何の疑問もなくそのような文章を書いている場合が多い。自分はこう理解したということを相手に伝える必要がある。 それはこういうことだよね?と表現を変えて相手に確認するということで、より正確な意図を知ることができる。face to faceのリアルタイムな会話であれば、一瞬で解決してしまうような問題でも文章となるとなかなかそういかないものである。
このようなことは、人とのコミュニケーションばかりでなく、仕様書や規格書を読むときなども同じである。この場合、その文書を書いた人とは直接的なコミュニケーションはとれないことの方が多い。読む人のスキルの差によって解釈の違いが出てしまう。そこにも「常識」の範囲内での解釈が要求されるが、その常識が人によって異なるのである。書かれてもいないことを信じ込んでいたり、曲解ともとれる解釈をする人に時に出会うこともある。それが間違っているということではない。
支離滅裂で分かりにくいことをくどくどと書いた感があるが、僕らソフトウェア開発者というのは、純粋に人間の頭の中にある形のないアイデアを技術力によって具現化するという無二の職業であり、外界との繋がりによる相互フィードバックによってのみ正しい方向を知ることができるのである。他者との関り合いは不可避であり、僕らは成長するためには、常に何かを吸収し続けるとともに、常に何かを放出し続けなければならない。
そして、どのような職業の専門分野でも突き詰めていくと人間とは何かということを考えさせられるのではないかと思う。僕自身純粋にプログラミングが好きということで続けてきたが、ソフトウェアは人間が作るものであり、そこには良くも悪くも人間の本質が否応なく投影されるということを強く感じている。
HTML5 videoでリアルタイム顔認識
以前、、ビデオのリアルタイムなヒストグラム表示を作ってみたが、思ったより高速だったので、もっと処理の重いものをやったらどうだろうと思い、JavaScriptで書かれた顔認識ソフトを利用して、ビデオに対してどのくらい可能なのかを試してみた。
JavaScriptによる顔認識ソフトは以下のものを利用。
中身を見ると、canvasにdrawImage()した画像をgetImageData()でピクセル情報を取得している。その際、モノクロ画像に変換してから認識している。また、動的にcanvasオブジェクトを生成してオリジナルの部分的な領域を抽出している。その先はちょっとブラックボックス。
で、ビデオのヒストグラム表示でやったときと同じように、ビデオを一旦canvasに縮小してdrawImageしてそのイメージに対して顔認識ソフトを適用してみた。
結果、非常い重い。1秒に2〜3コマ処理できる程度。β版と書かれているが、WebWorkerを利用したモードもあるので、それも試してみたが逆に重くなる。ヒストグラム表示のときもWebWorker版を作ったが、そのときもビデオの再生がカクカクしてしまうなど逆に遅くなった。ビデオとWebWorkerの組み合わせはどうも問題があるようだ。
そこで、JavaScriptのコードを改良することにした。顔認識の原理を知らないので、単純に機械的なコードの書き換えしかできないが、まず、以下を実行した。
1. 一時変数への代入
なぜか、以下のようなパターンが多い
x = foo[i].bar[j].func1(); y = foo[i].bar[j].func2(); z = foo[i].bar[j].func3();
これを
v = foo[i].bar[j]; x = v.func1(); y = v.func2(); z = v.func3();
とした
2. applyよりcall
なぜか、引数の数が固定なのに、わざわざ配列にしてapplyを実行している。配列を生成するのはムダだ。
fucn.apply(obj, [ arg1, arg2, arg3 ]);
これを以下のようにした。
func.call(obj, arg1, arg2, arg3);
3. for文の条件
一時変数への代入と同様であるが、以下のようなパターンが目立つ。
for (i = 0; i < foo[j].bar[k]; i++)
以下のようにした。
for (i = 0, n = foo[j].bar[k]; i < n; i++)
これらをやっても、それほどの効果はないだろうが、このようなコードを見るとつい直したくなる性分なので変更したというのが正直なところ。また、効果のなかったWebWorkerのコードをバッサリ削除し、自分好みに整形した。
結果は確かにあまり変わらない。そりゃそうだと思う。コードを単純に変更しただけはあまり効果はないので、もうちょっと効果のありそうな方法を次に試した。
4. canvasへdrawImage()するとき、もっと小さな画像にする
例えば 160x90 くらいにすると、かなり高速になる。でも、逆に認識率が低下してしまう。大きくもなく、小さくもなく、という適当な大きさにすればよさそうなので、ちょっと試してみて320x180に落ち着いた。
5. モノクロへの変換をやめてみる
情報量的にはカラーのままにした方が認識しやすいはずであるが、なぜかモノクロに変換しているので、カラーのまま実行したらどうなるかやってみた。結果、認識率にあまり変化はなさそうだった。なぜモノクロにしているのかわからない。
6. canvasオブジェクトの再利用
実行中にcreateElement()でcanvasオブジェクト複数生成している。DOM treeに結合しているわけではなく、drawImage()してイメージを部分的に切り出すために使っているようだ。これをビデオの再生中に毎回実行していたら遅いのは当たり前なので、生成したcanvasを再利用するようにした。ちなみに、canvasオブジェクトが37個生成されている。
以上の結果、画期的に高速になった。 ……と言いたいところだったが、多少高速になった程度。
人物の顔が映っていて著作権上問題のないビデオが見つからなかったので、結果だけを載せる。YouTubeをザッピングしていたら、顔認識のテストにまさにちょうどいい動画があった。AKB48の「頑張ろう、日本!!」の動画である。前回作った対話コマンドを使って最後のシーン付近で最も認識に成功しているものをコマ送りして選んだもの。実際に動作するところを載せたいが、canvasのgetImageData()を使っているのでドメインが異なるとセキュリティ例外が発生するし、そもそも著作権上できないだろう。顔認識に適した自由に使える動画はないだろうか?

実際の動作はこちらから確認できる。動画は前回と同じBig Buck BunnyとSintel。BBBは顔認識できないが、Sintelの方はちょっとだけ認識できるシーンがある。
高速になるだろうと期待して書き換えたソースはこちら。
今回はあまり有益な結果は得られなかったが、それでも十分楽しめた。
AKBのメンバーの顔と名前もちょっとは覚えたし...